
Aqua Data Studio下:
选定表,右击----->Tools----->Export Data
在右侧Objects视图中,自己选定的表已经打√,同时,你也可以选择多个,只要在复选框中打√就行。
----->Next,可以改变导出文件位置,以及编码等,还有部分特殊数据格式。
----->Next,等待导出,导出状态显示,completed即完成。
--------------------------------------------------------------------------------------------------------
查询建表语句
选定表,右击----->Script Object to Window as ----->CREATE,建表语句在右侧窗口显示,复制。
PL/SQL下:
在SQL窗口中,将建表语句粘贴,运行成功。[可能其中有的关键字和语句规则不一样,如果运行失败,请注意改动]
工具栏,Tools----->Text Importer...----->
 Open Data File 上传刚刚导出的txt文件,
Open Data File 上传刚刚导出的txt文件,第一次导入,一些配置选项可能不会自动分配,需要自己手动选择。
【Data from Textfile】File Data视图里,是你txt文件中的预览;
Configuraion--General--Fieldcount【选择字段数,比如表中有8列,则选8】
|--End at line-end / Name in header / Skip empty lines 勾选上【此情况下,其他情况按需勾选】
Field Start不必改动;
Field End 字段此处是以 , 结束,所以点击Character,右侧下拉框显示,即可;
Result Preview 结果预览,如果只显示某一列或者某几列
 则依次点击中间Fieldn字段-Field End (Character)即可【字段1-分隔符;字段二-分隔符...】;
则依次点击中间Fieldn字段-Field End (Character)即可【字段1-分隔符;字段二-分隔符...】;
5. 【Data to Oracle】
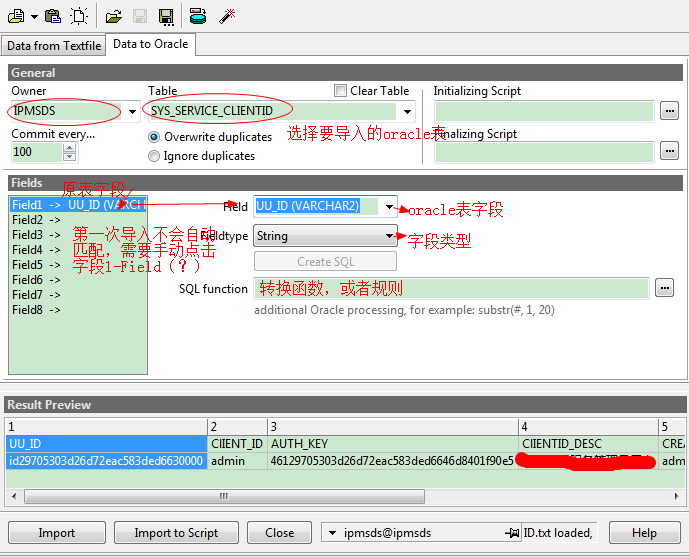
当Fields一一匹配完整,就可以点击Import,将数据导入啦。
【这是昨天用的方法,知道不是很有效率,但是由于是第一次迁移,选择了这个,以后有其他的,会继续录入】